xpath in python
前言
今天在开源中国看到一篇文章自动配置Google Hosts脚本,文章介绍了通过HTMLParse解析360GoogleHosts文件,实现自动更新本地host文件的方法。详情请参见原文。
正文
本文将通过XPath解析host文件,换一个途径实现host记录的解析。之所以选择XPath,主要是因为chrome浏览器的DevelopTool能够自动解析html文件的XPath,可以很方便的定位到要获取的html元素。
XPath定位元素
用chrome浏览器打开上文中提到的hosts文件所在的网页。在hosts记录上右键->”审查元素”,定位到
元素后,直接在元素上右键即可看到复制XPath菜单。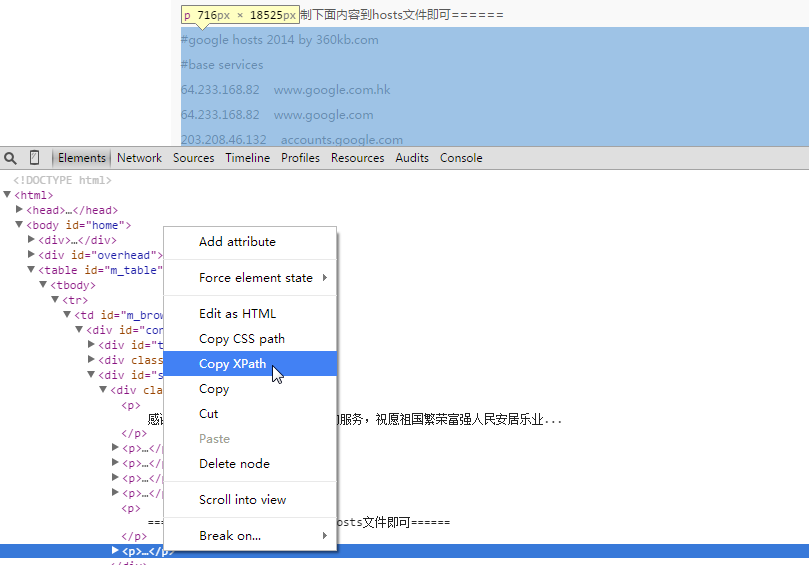
python处理XPath
刚接触python不久,搜索了一下,大家都推荐用lxml库,我就现学现用了:)
安装lxml
如果安装了pip,直接在python控制台输入
[安装lxml] 1pip install lxml如果没有安装pip环境,请先安装pip环境,具体请移步google
小试牛刀
有了XPath和lxml,用python可以优雅的解析上文中提及的网页,不罗嗦,直接上代码,新手,勿喷。。
[using XPath in python] 123456789101112from lxml import etreedef GetHosts(text):'''用XPath解析host内容'''try:tree = etree.HTML(text)nodes = tree.XPath("//*[@id='storybox']/div/p[7]",smart_strings=True)return etree.tostring(nodes[0])except:print("error to resolve the html ")pass
格式调整
通过上面代码取出来的字符还带有html标签,以下为截取的一部分内容:
需要通过小调整使文本能够直接应用在hosts文件中,这里我选择了粗暴的链式替换代码。
通过这样处理后的内容可以直接写入hosts文件咯。
后记
还可以通过csspath解析哦。
